Sorry for not updating this blog for long time. I will move my blog to http://blog.bimbelbee.com.
Thanks
Sorry for not updating this blog for long time. I will move my blog to http://blog.bimbelbee.com.
Thanks
 Issue
Issue  .
.
Things need to be checked
Microsoft support asked us to do several things for investigating this issue. From this we also knew how SharePoint’s alert actually works.
1. Check whether we can get the first notification mail from SharePoint when we subscription “Alert me”.
2. Check whether we will get a new record in content database.
· Actually, once we done some modification in library or list, the system will insert
a new record in database for "Mail Alert".
· We can run the following command to check whether this record has be inserted to DB :
SELECT * FROM dbo.EventCache ORDER BY eventtime DESC
3. Then, SharePoint timer job service will read the data from DB and send mail out.
· NOTE : The timer job service will run every 5 minutes by default.
· We also can run the following command to check it.
Stsadm –o getproperty –propertyname job-immediate-alerts
4. After that, the record will be deleted from content database.
|
Problem Solve
From that guidance, we just realized that our SharePoint Timer service was off. After turned it on, the alert back to normal. If the guidance doesn’t help on your problem. It should be another component that you need to check such as the SMTP server etc.
 Objective
Objective Usage
Just run below script to get the TSQL script. You can review the result first before run the result to disable/ enable SQL jobs. FYI, when trying to disable the jobs the script only execute the jobs that status is enable. To enable it back, just keep the result and replace @enable = 0 become @enable = 1. I just prevent not to enable job which status is disable before the script was executed.
Script
SET NOCOUNT ON
DECLARE @job_id UNIQUEIDENTIFIER
DECLARE @disable_job CHAR(1)
SET @disable_job = 'Y' -- Fill 'Y' to disable job .. 'N' to enable job
IF OBJECT_ID('tempdb..#sysjobs') IS NOT NULL
DROP TABLE #sysjobs
SELECT job_id INTO #sysjobs
FROM msdb..sysjobs
WHERE enabled = CASE @disable_job WHEN 'Y' THEN 1 ELSE 0 END
WHILE (1 = 1)
BEGIN
SELECT @job_id = job_id FROM #sysjobs
IF @@rowcount = 0
GOTO _EXIT
PRINT 'exec msdb..sp_update_job @job_id = ''' + CAST(@job_id AS VARCHAR(36))+ ''', @enabled = '
+ CASE @disable_job WHEN 'Y' THEN '0' ELSE '1' END
PRINT 'GO'
DELETE FROM #sysjobs WHERE job_id = @job_id
END
_EXIT:
DROP TABLE #sysjobs
SET NOCOUNT OFF
|
 Issue
Issue1. Determine logical name of file that we want to move
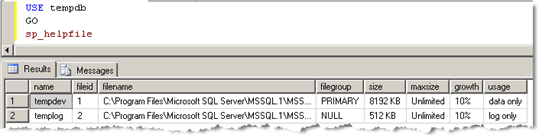
USE tempdb GO sp_helpfile |
On below sample, the logical name are tempdev and templog.
2. Move the data file using ALTER DATABASE statement
USE master GO ALTER DATABASE tempdb modify file (name = [logical name], filename = '[new location of file]') |
e.g.:
ALTER DATABASE tempdb modify file (name = tempdev, filename = 'D:\SQLDATA\tempdb.mdf') or ALTER DATABASE tempdb modify file (name = templog , filename = 'D:\SQLLOG\tempdb_log.ldf')
3. This alteration will confirm after we restart the SQL Server service. Stop than restart the SQL Server service. You should delete the old files manually.
Result
After this action, the error does not occur any more  . Meanwhile we still investigate why the error occurred. We also open ticket to Microsoft to help us investigate this issue.
. Meanwhile we still investigate why the error occurred. We also open ticket to Microsoft to help us investigate this issue.
 Background
Background Step by Step
1. Stop SQL Server service
2. Enter console mode by type cmd from start -> run
3. Go to folder where sqlservr.exe located e.g.: C:\Program Files\Microsoft SQL Server\MSSQL\Binn
4. Type sqlservr.exe -m for SQL Server is not use instance name) or sqlservr.exe -m -s[Instance Name] for SQL Server that use instance name.
5. Connect to the SQL Server use user with system administrator role
6. At the end, type Ctrl+C in console screen, type “Y” on “Do you wish to shutdown SQL Server (Y/N)?”
7. Start SQL Server service.
 If your application use SQL Server user with role as system administrator like “sa”, you may face problem when try to connect to SQL Server in Single Mode User because there is possibility the application already connect to the SQL Server before you do. If your application use SQL Server user with role as system administrator like “sa”, you may face problem when try to connect to SQL Server in Single Mode User because there is possibility the application already connect to the SQL Server before you do. |
 Background
BackgroundThe right value of the fill factor will upgrade the performance of the application. The fill factor value is a percentage between 0 to 100. This percentage specifies how much to fill the data pages after the index is created. A value of 100 means the pages will be full and will take the least amount of storage space. This setting should be used only when there will be no changes to the data, for example, on a read-only table. A lower value leaves more empty space on the data pages, which reduces the need to split data pages as indexes grow but requires more storage space. This setting is more appropriate when there will be changes to the data in the table.
The fill factor is implemented only when the index is created; it is not maintained after the index is created as data is added, deleted, or updated in the table. Trying to maintain the extra space on the data pages would defeat the purpose of originally using the fill factor because SQL Server would have to perform page splits to maintain the percentage of free space, specified by the fill factor, on each page as data is entered. Therefore, if the data in the table is significantly modified and new data added, the empty space in the data pages can fill. In this situation, the index can be re-created and the fill factor specified again to redistribute the data (SQL Server BOL 2000).
Therefore I created script for listing all indexes’s fill factor. There are 2 types of script. One for SQL 2000 and other for SQL 2005. For SQL 2005 also list value of the index fragmentation.
Script
SQL Server 2000
/*
Created by : Solihin ho - https://solihinho.wordpress.com
Compatibility : SQL 2000
*/
IF object_id('tempdb..#result') IS NOT NULL
DROP TABLE #result
CREATE TABLE #result
(
DBName sysname,
TableName sysname,
IndexName sysname,
[Rows] int,
[FillFactor] tinyint,
[TimeStamp] datetime
)
GO
sp_msforeachdb 'USE ?
INSERT #result (DbName, TableName, IndexName, [Rows], [FillFactor], [TimeStamp])
SELECT db_name() as DbName
,o.name as TableName
,i.name as IndexName
,i.rows as RowsCount
,i.OrigFillFactor
,GetDate() as [TimeStamp]
FROM sysindexes i
INNER JOIN sysobjects o ON i.id = o.id
WHERE i.indid > 0 and i.indid < 255
AND i.name NOT LIKE ''_WA_Sys_%'''
SELECT * FROM #Result
|
SQL Server 2005 and Next Version
/*
Created by : Solihin ho - https://solihinho.wordpress.com
Compatibility : SQL 2005 and next version
*/
IF object_id('tempdb..#result') IS NOT NULL
DROP TABLE #result
CREATE TABLE #result
(
DBName sysname,
TableName sysname,
IndexName sysname,
[Rows] int,
[FillFactor] tinyint,
Index_Fragmentation float,
page_count int,
[TimeStamp] datetime
)
GO
sp_msforeachdb 'USE ?
INSERT INTO #Result (DBName, TableName, IndexName
, [FillFactor], [Rows], Index_Fragmentation
, page_count, [TimeStamp])
SELECT
db_name() AS DbName
, B.name AS TableName
, C.name AS IndexName
, C.fill_factor AS IndexFillFactor
, D.rows AS RowsCount
, A.avg_fragmentation_in_percent
, A.page_count
, GetDate() as [TimeStamp]
FROM sys.dm_db_index_physical_stats(DB_ID(),NULL,NULL,NULL,NULL) A
INNER JOIN sys.objects B
ON A.object_id = B.object_id
INNER JOIN sys.indexes C
ON B.object_id = C.object_id AND A.index_id = C.index_id
INNER JOIN sys.partitions D
ON B.object_id = D.object_id AND A.index_id = D.index_id
WHERE C.index_id > 0'
SELECT * FROM #Result
|
What next?
You can schedule above script and keep the result in a table for reviewing next time. You can review the row count to see whether the table grow or not. Just decide the value of the table’s fill factor e.g.: 100% for read only table. For SQL 2005 script, you also review of the index fragmentation. You can review how fast the index become fragmented. You can set the fill factor until you get a best value for the index.

Script
Below the script for list index availability of the tables.
Result of the script
| Column Name | Description |
| TableName | Name of the table |
| SchemaName | Name of the schema |
| HasIndex | Yes if the table has an index vice versa |
| IndexName | Name of the index |
| IndexKeys | Keys of the index |
| IsPrimaryKey | Is this index a primary key? |
| IndexType | Type of the index whether clustered or non clustered |
/*
Created by : Solihin ho - https://solihinho.wordpress.com
Compatibility : SQL Server 2005 and next
*/
DECLARE @ObjectID INT, @IndexID INT
DECLARE @ObjectName SYSNAME, @SchemaName SYSNAME
DECLARE @ColumnName SYSNAME
DECLARE @IndexKeys NVARCHAR(1000)
IF OBJECT_ID ('tempdb..#Result') IS NOT NULL
DROP TABLE #Result
CREATE TABLE #Result
(
ObjectID INT,
ObjectName SYSNAME,
SchemaName SYSNAME,
IndexId INT,
IndexName SYSNAME NULL,
IndexType NVARCHAR(60),
IndexKeys NVARCHAR(1000),
HasIndex VARCHAR(3),
IsPrimaryKey BIT
)
INSERT INTO #Result (ObjectID, ObjectName, SchemaName, IndexId
, IndexName, IndexType, HasIndex, IsPrimaryKey)
SELECT o.object_id, o.name AS ObjectName
, s.name as SchemaName
, i.index_id, i.name AS IndexName
, i.type_desc
, 'No'
, i.is_primary_key
FROM sys.objects o
INNER JOIN sys.schemas s ON o.schema_id = s.schema_id
INNER JOIN sys.indexes i ON o.object_id = i.object_id
WHERE o.type = 'U'
--Index Keys
IF (OBJECT_ID('tempdb..#keys_temp') IS NOT NULL)
DROP TABLE #keys_temp
SELECT r.ObjectID, r.IndexId, c.name AS ColumnName
INTO #keys_temp
FROM #Result r
LEFT OUTER JOIN sys.index_columns ic
ON r.ObjectID = ic.object_id AND r.IndexID = ic.index_id
LEFT OUTER JOIN sys.columns c
ON c.column_id = ic.column_id AND r.ObjectID = c.object_id
WHERE r.IndexID > 0
WHILE (1 = 1)
BEGIN
SET @IndexKeys = ''
SET @ObjectID = NULL
SET @IndexID = NULL
SELECT TOP 1 @ObjectID = ObjectID, @IndexID = IndexID
FROM #keys_temp
ORDER BY ObjectID, IndexID
IF @ObjectID IS NULL
GOTO _Loop1
WHILE (1 = 1)
BEGIN
SET @ColumnName = NULL
SELECT TOP 1 @ColumnName = ColumnName
FROM #keys_temp
WHERE ObjectID = @ObjectID AND IndexID = @IndexID
ORDER BY ColumnName
IF @ColumnName IS NULL
GOTO _Loop2
SET @IndexKeys = @IndexKeys + @ColumnName + ', '
DELETE FROM #keys_temp
WHERE ObjectID = @ObjectID AND IndexID = @IndexID
AND ColumnName = @ColumnName
END
_Loop2:
UPDATE #Result SET IndexKeys = LEFT(@IndexKeys, LEN(@IndexKeys)-1)
WHERE ObjectID = @ObjectID AND IndexID = @IndexID
END
_Loop1:
DROP TABLE #keys_temp
IF OBJECT_ID('tempdb..#object_temp') IS NOT NULL
DROP TABLE #object_temp
SELECT DISTINCT ObjectName, SchemaName INTO #object_temp
FROM #Result
WHILE (1 = 1)
BEGIN
SET @ObjectName = NULL
SELECT TOP 1 @ObjectName = ObjectName, @SchemaName = SchemaName
FROM #object_temp
ORDER BY ObjectName, SchemaName
IF @ObjectName IS NULL
GOTO _Loop3
IF EXISTS (SELECT * FROM #Result WHERE ObjectName = @ObjectName
AND SchemaName = @SchemaName
AND IndexID > 0)
BEGIN
UPDATE #Result SET HasIndex = 'Yes'
WHERE ObjectName = @ObjectName AND SchemaName = @SchemaName
END
DELETE FROM #object_temp WHERE ObjectName = @ObjectName
AND SchemaName = @SchemaName
END
_Loop3:
SELECT ObjectName AS TableName
, SchemaName
, HasIndex
, IndexName
, IndexKeys
, CASE WHEN IsPrimaryKey = 1 Then 'Yes' ELSE 'No' END AS IsPrimaryKey
, IndexType
FROM #Result
ORDER BY ObjectName, SchemaName
|
This is the result when I ran the script on AdventureWorks database.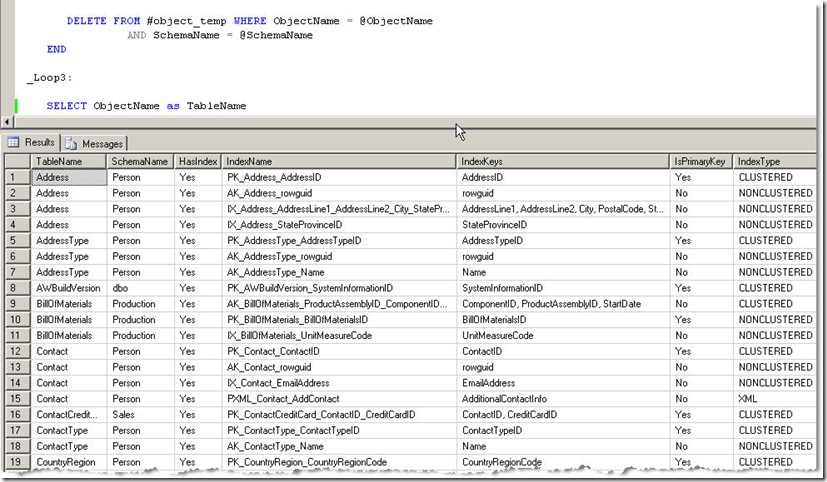
 Background
Background I reckoned this job created by the earlier DBA because in our database server since we have an issue with disk space that using for database log. But it still little strange because there is another job that already backup the log to another disk. So I guess the DBA didn’t know the consequence of this action and so did I before this issue came up. I thought shrink log file and backup log with no_log is one whole packet. We could not shrink the log since the log space should be truncate first. It will truncate the log space if we backup the database or backup the log either we backup it to another device or backup log with no_log.
| To see log size and percentage the usage use command DBCC SQLPERF (LOGSPACE) . We only can shrink free space of the log. |
Scenario
Let’s see below scenario. 1st I will run it on SQL Server 2000
--1. Create TestLog Database
CREATE DATABASE TestDB
GO
--2. Active on TestLog database and set for FULL recovery model
use TestDB
GO
--Recovery model should be FULL
ALTER DATABASE TestDB SET RECOVERY FULL
GO
--3. Create Table
CREATE TABLE TestTbl
(
ID INT,
Description CHAR(100)
)
GO
--4. Insert Data
INSERT INTO TestTbl VALUES(1, 'This is first record')
GO
--5. Backup Full Database
BACKUP DATABASE TestDB TO DISK = 'C:\temp\BK_FULL.bak'
GO
--6. Insert Another Data
INSERT INTO TestTbl VALUES(2, 'This is 2nd record')
GO
--7. Backup log to disk #1
BACKUP LOG TestDB TO DISK = 'C:\temp\BK_LOG.bak'
GO
--8. Insert Data again
INSERT INTO TestTbl VALUES (3, 'This is 3rd record')
GO
--9. Backup log to disk #2
BACKUP LOG TestDB TO DISK = 'C:\temp\BK_LOG.bak'
GO
--10. Insert Data again
INSERT INTO TestTbl VALUES (4, 'This is 4rd record')
GO
--11. Upss disk nearly full, DBA do shrink with no_log and shrink the file
BACKUP LOG TestDB WITH NO_LOG
GO
DBCC SHRINKFILE('TestDB_Log')
GO
--12. Insert Data again
INSERT INTO TestTbl VALUES (5, 'This is 5th record')
GO
--13. Backup log to disk #3
BACKUP LOG TestDB TO DISK = 'C:\temp\BK_LOG.bak'
GO
--14. Another Upss .. DBA delete all data
DELETE FROM TestTbl
GO
--15. Let's analyze the backup file
RESTORE HEADERONLY FROM DISK = 'C:\temp\BK_FULL.bak'
RESTORE HEADERONLY FROM DISK = 'C:\temp\BK_LOG.bak'
|
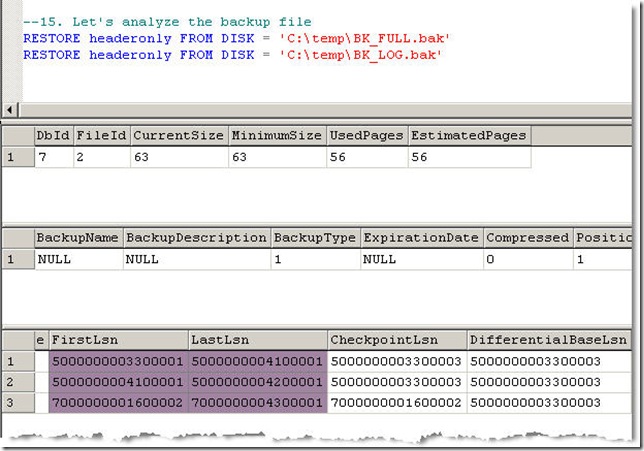
And Here is the result.
Let’s analyze the highlight result. #1 LastLsn is similar with #2 FirstLsn but #2 LastLsn is not similar with #3 FirstLsn, It is caused by Backup Log with NO_LOG. It cause the chain of the transaction log is broken and we cannot restore transaction log #3 and the following files.
Now, I’ll try to run this scenario in SQL Server 2005 and here is the result. As we see, 1st and 2nd backup log is successful. But when trying backup log for the 3rd times it is failed because before run the 3rd backup log we have already run backup log with no_log. SQL Server 2005 does not allow the transaction log file broken. It is really useful enhancement from SQL Server in order to make sure that our transaction log is always is one chain and we are as DBA know if there is an issue in our backup transaction log.

Real World
As a DBA, it is very important to be able recover a damaged database that caused with many factors. It can be caused by hardware (hard disk) failure, electricity problem, software bugs, and human error. Rather than hardware error, human error is #1 factor that could make database damage e.g: delete data accidentally, drop database, wrong update data etc.
Some situations need DBA could recovery the data until specified time before the database was damaged. There is some technics to make it possible but this time what we discuss is using database transaction log. What we need to do for the recovery is restore database from full database backup + differential database backup + transaction log backup.
DBA should review the DR (Disaster Recovery) strategy periodically. The nice DR strategy is when the disaster occurred, the recovery succeed recover data as much as possible. We need to try simulate the disaster and try to recover the data. It is important to make sure that our DR strategy procedure is already correct and not miss something.
Backup Strategy
Before I explain about the recovery, it is better that we know the backup strategy.
1. Full backup every week (usually on weekend)
| BACKUP DATABASE <database name> TO <backup device> |
2. Differential backup every day
| BACKUP DATABASE <database name> TO <backup device> WITH DIFFERENTIAL |
3. Transaction Log backup every x hours / x minutes
| BACKUP LOG <database name> TO <backup device> |
Recovery Strategy
1. Restore Full Backup
2. Restore latest Differential Backup which is running after the full backup on step 1
e.g. : if full backup on Sunday Night and Diff backup everyday night , when the disaster occur on Thursday we just use the differential backup on Wednesday.
3. Restore Transaction Backup which is running after latest any database backup model
Restore log little bit difficult than just full and diff. We have to find the continuous transaction log with the latest backup. BACKUP LOG with option NO_LOG or TRUNCATE_ONLY should break the chain.
Statement for Restore from FULL and DIFFERENTIAL backup: RESTORE DATABASE <database_name> FROM <backup_device> Statement for restore TRANSACTION LOG backup: RESTORE LOG <database_name> FROM <backup_device> For further option, read SQL Server BOL. |
Note to RECOVERY / NORECOVERY option, use NORECOVERY option if there is another backup file that should be restored. Use RECOVERY if the final file backup have restored.
Requisite
Database recovery model should not be in SIMPLE mode. You can use ALTER DATABASE to change the recovery model. If you try to backup log database with SIMPLE recovery model, error should be occurred. Note if you use BULK_LOGGED recovery model, you cannot restore to the point in time if there are any bulk logged operations in transaction log.
Msg 4208, Level 16, State 1, Line 1
The statement BACKUP LOG is not allowed while the recovery model is SIMPLE. Use BACKUP DATABASE or change the recovery model using ALTER DATABASE.
Msg 3013, Level 16, State 1, Line 1
BACKUP LOG is terminating abnormally.
Disaster Recovery Scenario
As mention on backup strategy, we full backup every weekend, differential backup every night on weekdays and backup log every hours. Below script is illustration about the disaster where the DBA delete all data accidentally. DBA have to recovery the database with minimal loss data. We should recover the data to the point in time before the disaster happened.
Disaster Scenario
--1. Create Database DR Testing
CREATE DATABASE TestDR;
GO
--2. Active on TestDR database
USE TestDR
GO
--Recovery model should be FULL
ALTER DATABASE TestDR SET RECOVERY FULL
GO
--3. Create Table
CREATE TABLE Orders
(
Code INT PRIMARY KEY,
Timestamp DATETIME
)
GO
--4. Assume there are data already exists in this table
INSERT INTO dbo.Orders VALUES (1, '3 Jan 2009 09:00:00.000')
INSERT INTO dbo.Orders VALUES (2, '3 Jan 2009 12:00:00.000')
INSERT INTO dbo.Orders VALUES (3, '3 Jan 2009 16:00:00.000')
GO
--5. Full backup run every sunday on 4 Jan 2009 to C:\temp\TestDR_Full.bak
BACKUP DATABASE TestDR TO DISK = 'C:\temp\BK_Full_090104.bak'
WITH DESCRIPTION = 'Full Backup ON 4 Jan 2009', NAME = 'Full Backup'
GO
--6. Transactions on 5 Jan 2009 and BACKUP LOG every hours
INSERT INTO dbo.Orders VALUES (4, '5 Jan 2009 07:45:00.000')
GO
BACKUP LOG TestDR TO DISK = 'C:\temp\BK_Log_090105.bak'
WITH DESCRIPTION = 'Log Backup ON 5 Jan 2009 08:00:00.000', NAME = 'Log Backup'
GO
INSERT INTO dbo.Orders VALUES (5, '5 Jan 2009 11:30:00.000')
GO
BACKUP LOG TestDR TO DISK = 'C:\temp\BK_Log_090105.bak'
WITH DESCRIPTION = 'Log Backup ON 5 Jan 2009 12:00:00.000', NAME = 'Log Backup'
GO
--7. Backup Diff after office hours
BACKUP DATABASE TestDR TO DISK = 'C:\temp\BK_DIFF_090105.bak'
WITH DIFFERENTIAL, DESCRIPTION = 'Diff Backup ON 5 Jan 2009 22:00:00.000'
,NAME = 'Diff Backup'
--8. Transactions on 6 Jan 2009 and BACKUP LOG every hours
INSERT INTO dbo.Orders VALUES (6, '6 Jan 2009 09:35:00.000')
GO
BACKUP LOG TestDR TO DISK = 'C:\temp\BK_Log_090106.bak'
WITH DESCRIPTION = 'Log Backup ON 6 Jan 2009 10:00:00.000', NAME = 'Log Backup'
GO
INSERT INTO dbo.Orders VALUES (7, '6 Jan 2009 13:10:00.000')
GO
BACKUP LOG TestDR TO DISK = 'C:\temp\BK_Log_090106.bak'
WITH DESCRIPTION = 'Log Backup ON 6 Jan 2009 14:00:00.000', NAME = 'Log Backup'
GO
INSERT INTO dbo.Orders VALUES (7, '6 Jan 2009 14:23:00.000')
GO
--9. 14.35 AM, DBA delete all data accidentally.
DELETE FROM dbo.Orders
|
Recovery Scenario
Before we restore the database, awhile we review what we have and need to do for recovery.
1. We need latest full backup. We have full backup at Jan 4th, 2009 on BK_Full_090104.bak
2. Since disaster occur on Tuesday Jan 6th, 2009 we have to apply latest differential backup which is on Jan 5th, 2009 on BK_DIFF_090105.bak
3. Last but not least is we also need apply the transaction log backup which is on Jan 6th, 2009 on BK_LOG_090106.bak. Since we backup the transaction log twice, we need to apply every file that we backup before we set the database to RECOVERY mode. If the transaction log backup file not in the chain, it should be show the error message like below
Msg 4326, Level 16, State 1, Line 1
The log in this backup set terminates at LSN 27000000017500001, which is too early to apply to the database.
A more recent log backup that includes LSN 27000000019300001 can be restored.
Msg 3013, Level 16, State 1, Line 1
RESTORE LOG is terminating abnormally.
--1. Restore from Full Backup With NORECOVERY option RESTORE DATABASE TestDR FROM DISK = 'C:\Temp\BK_FULL_090104.bak' WITH NORECOVERY GO --2. Restore from latest Diff Backup WITH NORECOVERY option RESTORE DATABASE TestDR FROM DISK = 'C:\Temp\BK_DIFF_090105.bak' WITH NORECOVERY GO --3. Restore from Transaction Log File 1 and File 2 RESTORE LOG TestDR FROM DISK = 'C:\Temp\BK_LOG_090106.bak' WITH NORECOVERY, File = 1 GO RESTORE LOG TestDR FROM DISK = 'C:\Temp\BK_LOG_090106.bak' WITH NORECOVERY, File = 2 GO --4. Use RECOVERY option so that the database is available again RESTORE DATABASE TestDR WITH RECOVERY GO |
 Recovery scenario above assume TestDR database is not exist anymore in the server (DROP DATABASE). If you want restore as another database, use MOVE option since we need change the filename for the restored database. Using RESTORE FILELISTONLY to get information about the physical and logical name of the backup device, Recovery scenario above assume TestDR database is not exist anymore in the server (DROP DATABASE). If you want restore as another database, use MOVE option since we need change the filename for the restored database. Using RESTORE FILELISTONLY to get information about the physical and logical name of the backup device, |
Restore HeaderOnly
If you see the recovery scenario is quite simple, isn’t it? But if in the real world I believe the scenario more complex. To analyze it is possible or not to restore until the specified time, we can use RESTORE HEADERONLY statement. Restore HeaderOnly returns a result set containing all the backup header information for all backup sets on a particular backup device. With this information, you can decide the file # that you need to be restored. There is information about what time the backup was performed. This information is needed by DBA that want restore the data until specified time.
| RESTORE HEADERONLY FROM <backup device> |
Let’s examine the FirstLSN, LastLSN, and DatabaseBackupLSN column from above scenario.
DatabaseBackupLSN contains LSN (Log Sequence Number) of the most recent full database backup. In above picture, we can see that Differential backup and Transaction Log backup contain value FirstLSN of full database backup. It means our differential backup and transaction log backup in the same chain with the full database backup. So BK_DIFF_090105.bak could be restored after we restore the full database backup.
Now we check the transaction log backup file. Note the LastLSN of the differential backup. The value should be in the range between FirstLSN and LastLSN on transaction log. We can see 27000000019300001 in the range between 27000000017600001 and 27000000019400001 in transaction log file #1. So file #1 could be restored. How about file #2. Note the FirstLSN of file #2 should be as same as LastLSN of file #1. So file #2 of transaction log could be restored also.
BACKUP LOG WITH NO_LOG could make the chain of the transaction log break. The value between files in transaction log won’t be continuous (FirstLSN file N should be same with LastLSN file N-1 where N > 1).
 Background
Background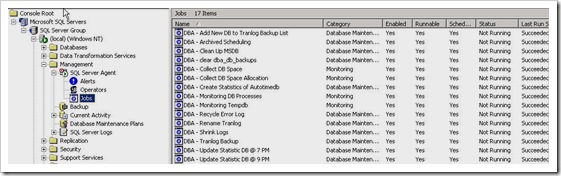
If using SQL Server Management Studio, it can be accessed under SQL Server Agent -> Jobs (see below picture)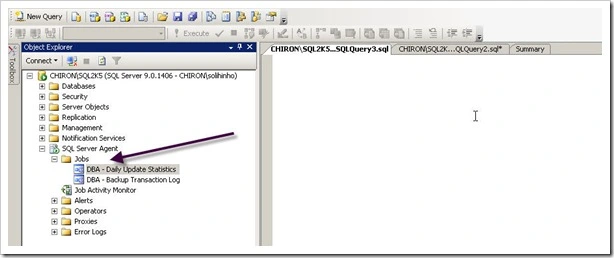
The issue is little difficult for me to review the schedule of the jobs. I have to click the each job and take note of each schedule. Since all these jobs keep on MSDB database, we are able to query the jobs within its schedule. When we have many jobs both maintenance or monitoring job etc, as a DBA we have to review the time when the jobs will be running. It is important to make our SQL Server load is balance which is mean not very heavy in one time but very light in another time.
The jobs general information keep in msdb.dbo.sysjobs table and the schedule keep in msdb.dbo.sysjobschedules (SQL 2000) or msdb.dbo.sysschedules (SQL 2005 and next). Read SQL Server Book Online (BOL) for further information about the columns of these tables.
Script
To make the main script simpler, I create 3 functions. Just run below script on master database. Actually you can it to another database and don’t forget to change the main query. These 3 functions valid for SQL Server 2000 and next. But there is little differences on the main query since there is a difference schema on table msdb.dbo.sysjobschedules.
USE master
GO
CREATE FUNCTION fn_freq_interval_desc(@freq_interval INT)
RETURNS VARCHAR(1000)
AS
BEGIN
DECLARE @result VARCHAR(1000)
SET @result = ''
IF (@freq_interval & 1 = 1)
SET @result = 'Sunday, '
IF (@freq_interval & 2 = 2)
SET @result = @result + 'Monday, '
IF (@freq_interval & 4 = 4)
SET @result = @result + 'Tuesday, '
IF (@freq_interval & 8 = 8)
SET @result = @result + 'Wednesday, '
IF (@freq_interval & 16 = 16)
SET @result = @result + 'Thursday, '
IF (@freq_interval & 32 = 32)
SET @result = @result + 'Friday, '
IF (@freq_interval & 64 = 64)
SET @result = @result + 'Saturday, '
RETURN(LEFT(@result,LEN(@result)-1))
END
GO
CREATE FUNCTION fn_Time2Str(@time INT)
RETURNS VARCHAR(10)
AS
BEGIN
DECLARE @strtime CHAR(6)
SET @strtime = RIGHT('000000' + CONVERT(VARCHAR,@time),6)
RETURN LEFT(@strtime,2) + ':' + SUBSTRING(@strtime,3,2) + ':' + RIGHT(@strtime,2)
END
GO
CREATE FUNCTION fn_Date2Str(@date INT)
RETURNS VARCHAR(10)
AS
BEGIN
DECLARE @strdate CHAR(8)
SET @strdate = LEFT(CONVERT(VARCHAR,@date) + '00000000', 8)
RETURN RIGHT(@strdate,2) + '/' + SUBSTRING(@strdate,5,2) + '/' + LEFT(@strdate,4)
END
|
Main query for SQL Server 2000
revise: May 18, 2009 : fixed inaccurate next run date
/*
Created by Solihin Ho - https://solihinho.wordpress.com
Usage : Change the value of variable @Filter
'Y' --> display only enabled job
'N' --> display only disabled job
'A' --> display all job
'X' --> display job which is duration already end
*/
DECLARE @Filter CHAR(1)
SET @Filter = 'A'
DECLARE @sql VARCHAR(8000)
DECLARE @is_sysadmin INT
DECLARE @job_owner sysname
IF OBJECT_ID('tempdb..#xp_results') IS NOT NULL
BEGIN
DROP TABLE #xp_results
END
CREATE TABLE #xp_results (
job_id UNIQUEIDENTIFIER NOT NULL,
last_run_date INT NOT NULL,
last_run_time INT NOT NULL,
next_run_date INT NOT NULL,
next_run_time INT NOT NULL,
next_run_schedule_id INT NOT NULL,
requested_to_run INT NOT NULL,
request_source INT NOT NULL,
request_source_id sysname COLLATE database_default NULL,
running INT NOT NULL,
current_step INT NOT NULL,
current_retry_attempt INT NOT NULL,
job_state INT NOT NULL
)
SELECT @is_sysadmin = ISNULL(IS_SRVROLEMEMBER(N'sysadmin'), 0)
SELECT @job_owner = SUSER_SNAME()
INSERT INTO #xp_results
EXECUTE master.dbo.xp_sqlagent_enum_jobs @is_sysadmin, @job_owner
SET @sql = '
SELECT
j.Name AS JobName
, c.Name AS Category
, CASE j.enabled WHEN 1 THEN ''Yes'' else ''No'' END as Enabled
, CASE s.enabled WHEN 1 THEN ''Yes'' else ''No'' END as Scheduled
, j.Description
, CASE s.freq_type
WHEN 1 THEN ''Once''
WHEN 4 THEN ''Daily''
WHEN 8 THEN ''Weekly''
WHEN 16 THEN ''Monthly''
WHEN 32 THEN ''Monthly relative''
WHEN 64 THEN ''When SQL Server Agent starts''
WHEN 128 THEN ''Start whenever the CPU(s) become idle'' END as Occurs
, CASE s.freq_type
WHEN 1 THEN ''O''
WHEN 4 THEN ''Every ''
+ convert(varchar,s.freq_interval)
+ '' day(s)''
WHEN 8 THEN ''Every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' weeks(s) on ''
+ master.dbo.fn_freq_interval_desc(s.freq_interval)
WHEN 16 THEN ''Day '' + convert(varchar,s.freq_interval)
+ '' of every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' month(s)''
WHEN 32 THEN ''The ''
+ CASE s.freq_relative_interval
WHEN 1 THEN ''First''
WHEN 2 THEN ''Second''
WHEN 4 THEN ''Third''
WHEN 8 THEN ''Fourth''
WHEN 16 THEN ''Last'' END
+ CASE s.freq_interval
WHEN 1 THEN '' Sunday''
WHEN 2 THEN '' Monday''
WHEN 3 THEN '' Tuesday''
WHEN 4 THEN '' Wednesday''
WHEN 5 THEN '' Thursday''
WHEN 6 THEN '' Friday''
WHEN 7 THEN '' Saturday''
WHEN 8 THEN '' Day''
WHEN 9 THEN '' Weekday''
WHEN 10 THEN '' Weekend Day'' END
+ '' of every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' month(s)'' END AS Occurs_detail
, CASE s.freq_subday_type
WHEN 1 THEN ''Occurs once at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
WHEN 2 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Seconds(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time)
WHEN 4 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Minute(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time)
WHEN 8 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Hour(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time) END AS Frequency
, CASE WHEN s.freq_type = 1 THEN ''On date: ''
+ master.dbo.fn_Date2Str(active_start_date)
+ '' At time: ''
+ master.dbo.fn_Time2Str(s.active_start_time)
WHEN s.freq_type < 64 THEN ''Start date: ''
+ master.dbo.fn_Date2Str(s.active_start_date)
+ '' end date: ''
+ master.dbo.fn_Date2Str(s.active_end_date) END as Duration
, master.dbo.fn_Date2Str(xp.next_run_date) + '' ''
+ master.dbo.fn_Time2Str(xp.next_run_time) AS Next_Run_Date
FROM msdb.dbo.sysjobs j (NOLOCK)
INNER JOIN msdb.dbo.sysjobschedules s (nolock) ON j.job_id = s.job_id
INNER JOIN msdb.dbo.syscategories c (NOLOCK) ON j.category_id = c.category_id
INNER JOIN #xp_results xp (NOLOCK) ON j.job_id = xp.job_id
WHERE 1 = 1
@Filter
ORDER BY j.name'
IF @Filter = 'Y'
SET @sql = REPLACE(@sql,'@Filter',' AND j.enabled = 1 ')
ELSE
IF @Filter = 'N'
SET @sql = REPLACE(@sql,'@Filter',' AND j.enabled = 0 ')
ELSE
IF @Filter = 'X'
SET @sql = REPLACE(@sql,'@Filter',
'AND s.active_end_date < convert(varchar(8),GetDate(),112) ')
ELSE
SET @sql = REPLACE(@sql,'@Filter','')
EXEC(@sql)
|
Main Query for SQL Server 2005 and next version
/*
Created by Solihin Ho - https://solihinho.wordpress.com
Usage : Change the value of variable @Filter
'Y' --> display only enabled job
'N' --> display only disabled job
'A' --> display all job
'X' --> display job which is duration already end
*/
DECLARE @Filter CHAR(1)
SET @Filter = 'A'
DECLARE @sql VARCHAR(8000)
DECLARE @is_sysadmin INT
DECLARE @job_owner sysname
IF OBJECT_ID('tempdb..#xp_results') IS NOT NULL
BEGIN
DROP TABLE #xp_results
END
CREATE TABLE #xp_results (
job_id UNIQUEIDENTIFIER NOT NULL,
last_run_date INT NOT NULL,
last_run_time INT NOT NULL,
next_run_date INT NOT NULL,
next_run_time INT NOT NULL,
next_run_schedule_id INT NOT NULL,
requested_to_run INT NOT NULL,
request_source INT NOT NULL,
request_source_id sysname COLLATE database_default NULL,
running INT NOT NULL,
current_step INT NOT NULL,
current_retry_attempt INT NOT NULL,
job_state INT NOT NULL)
SELECT @is_sysadmin = ISNULL(IS_SRVROLEMEMBER(N'sysadmin'), 0)
SELECT @job_owner = SUSER_SNAME()
INSERT INTO #xp_results
EXECUTE master.dbo.xp_sqlagent_enum_jobs @is_sysadmin, @job_owner
SET @sql = '
SELECT
j.Name AS JobName
, c.Name AS Category
, CASE j.enabled WHEN 1 THEN ''Yes'' else ''No'' END as Enabled
, CASE s.enabled WHEN 1 THEN ''Yes'' else ''No'' END as Scheduled
, j.Description
, CASE s.freq_type
WHEN 1 THEN ''Once''
WHEN 4 THEN ''Daily''
WHEN 8 THEN ''Weekly''
WHEN 16 THEN ''Monthly''
WHEN 32 THEN ''Monthly relative''
WHEN 64 THEN ''When SQL Server Agent starts''
WHEN 128 THEN ''Start whenever the CPU(s) become idle'' END as Occurs
, CASE s.freq_type
WHEN 1 THEN ''O''
WHEN 4 THEN ''Every ''
+ convert(varchar,s.freq_interval)
+ '' day(s)''
WHEN 8 THEN ''Every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' weeks(s) on ''
+ master.dbo.fn_freq_interval_desc(s.freq_interval)
WHEN 16 THEN ''Day '' + convert(varchar,s.freq_interval)
+ '' of every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' month(s)''
WHEN 32 THEN ''The ''
+ CASE s.freq_relative_interval
WHEN 1 THEN ''First''
WHEN 2 THEN ''Second''
WHEN 4 THEN ''Third''
WHEN 8 THEN ''Fourth''
WHEN 16 THEN ''Last'' END
+ CASE s.freq_interval
WHEN 1 THEN '' Sunday''
WHEN 2 THEN '' Monday''
WHEN 3 THEN '' Tuesday''
WHEN 4 THEN '' Wednesday''
WHEN 5 THEN '' Thursday''
WHEN 6 THEN '' Friday''
WHEN 7 THEN '' Saturday''
WHEN 8 THEN '' Day''
WHEN 9 THEN '' Weekday''
WHEN 10 THEN '' Weekend Day'' END
+ '' of every ''
+ convert(varchar,s.freq_recurrence_factor)
+ '' month(s)'' END AS Occurs_detail
, CASE s.freq_subday_type
WHEN 1 THEN ''Occurs once at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
WHEN 2 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Seconds(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time)
WHEN 4 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Minute(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time)
WHEN 8 THEN ''Occurs every ''
+ convert(varchar,s.freq_subday_interval)
+ '' Hour(s) Starting at ''
+ master.dbo.fn_Time2Str(s.active_start_time)
+ '' ending at ''
+ master.dbo.fn_Time2Str(s.active_end_time) END AS Frequency
, CASE WHEN s.freq_type = 1 THEN ''On date: ''
+ master.dbo.fn_Date2Str(s.active_start_date)
+ '' At time: ''
+ master.dbo.fn_Time2Str(s.active_start_time)
WHEN s.freq_type < 64 THEN ''Start date: ''
+ master.dbo.fn_Date2Str(s.active_start_date)
+ '' end date: ''
+ master.dbo.fn_Date2Str(s.active_end_date) END as Duration
, master.dbo.fn_Date2Str(xp.next_run_date) + '' ''
+ master.dbo.fn_Time2Str(xp.next_run_time) AS Next_Run_Date
FROM msdb.dbo.sysjobs j (NOLOCK)
INNER JOIN msdb.dbo.sysjobschedules js (NOLOCK) ON j.job_id = js.job_id
INNER JOIN msdb.dbo.sysschedules s (NOLOCK) ON js.schedule_id = s.schedule_id
INNER JOIN msdb.dbo.syscategories c (NOLOCK) ON j.category_id = c.category_id
INNER JOIN #xp_results xp (NOLOCK) ON j.job_id = xp.job_id
WHERE 1 = 1
@Filter
ORDER BY j.name'
IF @Filter = 'Y'
SET @sql = REPLACE(@sql,'@Filter',' AND j.enabled = 1 ')
ELSE
IF @Filter = 'N'
SET @sql = REPLACE(@sql,'@Filter',' AND j.enabled = 0 ')
ELSE
IF @Filter = 'X'
SET @sql = REPLACE(@sql,'@Filter',
'AND s.active_end_date < convert(varchar(8),GetDate(),112) ')
ELSE
SET @sql = REPLACE(@sql,'@Filter','')
EXEC(@sql)
|
Below sample result of above script 
